No Feed? No Problem!
Call me old but I’m a big fan of RSS feeds. It moves the backup of content to a location of your choosing, saves your email inbox being spammed from all the newsletters you’ve signed up to and RSS readers usually allow you to view all the stuff you’ve subscribed to in one place.
However, it’s no secret that RSS is now a shadow of it’s former self in the early and mid 2000’s. Popular social media networks and blogging sites, such as Medium and Twitter, treat it very much this way with limited to no support. As such, I am sometimes pushed to find other ways to pull content into my reader.
This is what this article is about, reconnoitring websites to find API endpoints that can be parsed to retrieve new news articles.
Web Scraping
Some people inevitably just suggest to “just scrape the webpage nerd”. True, using something like HTML XPATH scraping or Selenium to pull new articles is something you can do and I have done in the past. But it comes with a couple downsides:
- Site content is sometimes dynamically generated, meaning HTML XPATH definitions either don’t line up properly or are just not present in the HTML document.
- The site’s Web Application Firewall (WAF) may block attempts to scrape a site
It’s really only useful when the application’s API endpoint that retrieves the articles is locked to their domains. However, if you just find the endpoint that actually grabs the data that’s plugged into the application and are able to parse it, you do not have to worry about either of these things.
Finding An Endpoint
So, we have a theory. Here’s an example!
The Warhammer Community News & Features website does not have a RSS feed I could find, but it does have a rich assortment of articles I would like to have automatically imported into my reader.
Yes I am a massive nerd shut up
This content is all dynamically generated using JavaScript, the content does not tend to appear in reliable locations in the flat HTTP response of this page.
So, I began hunting and very quickly noticed an endpoint that returns the raw metadata of each article:
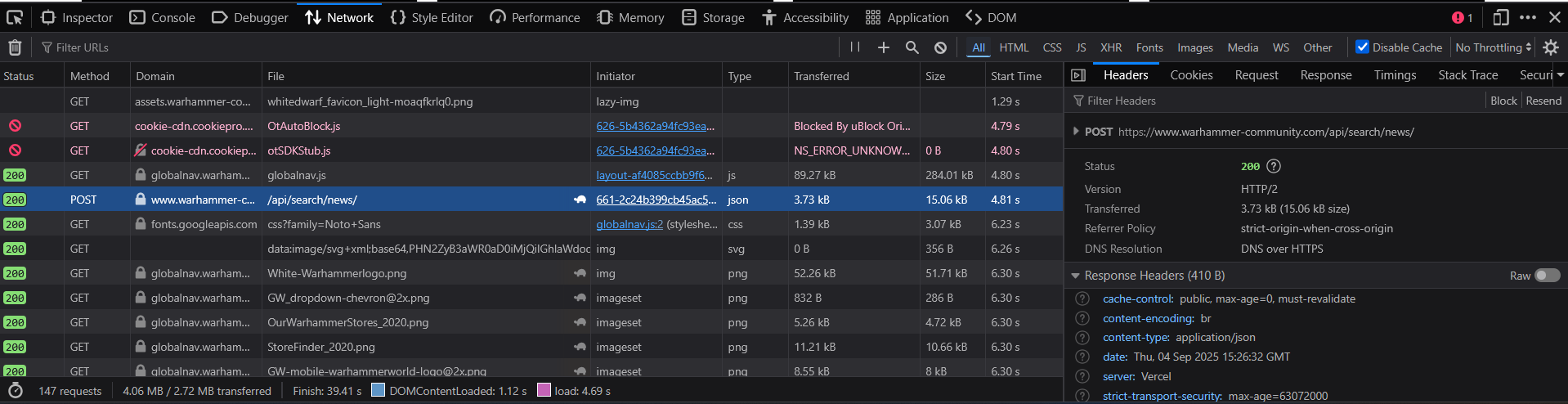
The response body for this API request always looked something like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
{
"news": [
{
"title": "Warhammer 40,000: Space Marine 2 celebrates one year with its biggest update yet",
"site": "en-gb",
"slug": "warhammer-40000-space-marine-2-celebrates-one-year-with-its-biggest-update-yet",
"excerpt": "Patch 10 is bursting with good stuff.",
"image": {
"path": "sm2_patch10-sep04-1-feature-e8tbpbdsdc.jpg",
"alt": null,
"width": 1455,
"height": 900,
"focus": "50% 50%"
},
"collection": "articles",
"game_system": {
"light": {
"path": "gs-icon-dark_warhammer40,000.svg",
"alt": null,
"width": "400",
"height": "400",
"focus": "50% 50%"
},
"dark": {
"path": "gs-icon-light_warhammer40,000.svg",
"alt": null,
"width": "400",
"height": "400",
"focus": "50% 50%"
}
},
"topics": [
{
"title": "Video Games",
"slug": "video-games"
},
{
"title": "Space Marines",
"slug": "space-marines"
},
{
"title": "Warhammer 40,000",
"slug": "warhammer-40000"
}
],
"date": "04 Sep 25",
"hide_date": false,
"hide_read_time": false,
"interaction_time": "2 min",
"uri": "/articles/gyfk7xmx/warhammer-40000-space-marine-2-celebrates-one-year-with-its-biggest-update-yet",
"id": "1b818454-cd66-41f2-81b1-244318f3933a",
"uuid": "gyfk7xmx"
},
// More articles under here
]
}
This is exactly what we need in order to form a definition in our reader as we have the 3 main components:
- Where to find new articles
- The title of each article
- The link to each article
And better yet, this required absolutely no tokens or authentication from the website to query it:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
curl 'https://www.warhammer-community.com/api/search/news/' -X POST --data-raw '{"sortBy":"date_desc","category":"","collections":["articles"],"game_systems":[],"index":"news","locale":"en-gb","page":0,"perPage":16,"topics":[]}' | jq
{
"news": [
{
"title": "Lady Malys stands tall over the new Codex: Drukhari",
"site": "en-gb",
"slug": "lady-malys-stands-tall-over-the-new-codex-drukhari",
"excerpt": "Be evil, it’s fun!",
"image": {
"path": "40k_drukhari-sep8-1-feature-i4a58lgauo.jpg",
"alt": null,
"width": 1455,
"height": 900,
"focus": "50% 50%"
},
"collection": "articles",
"game_system": {
"light": {
"path": "gs-icon-dark_warhammer40,000.svg",
"alt": null,
"width": "400",
"height": "400",
"focus": "50% 50%"
},
"dark": {
"path": "gs-icon-light_warhammer40,000.svg",
"alt": null,
"width": "400",
"height": "400",
"focus": "50% 50%"
}
},
"topics": [
{
"title": "Model Reveal",
"slug": "model-reveal"
},
{
"title": "Drukhari",
"slug": "drukhari"
},
{
"title": "Warhammer 40,000",
"slug": "warhammer-40000"
}
],
"date": "08 Sep 25",
"hide_date": false,
"hide_read_time": false,
"interaction_time": "2 min",
"uri": "/articles/5jk5xmlb/lady-malys-stands-tall-over-the-new-codex-drukhari",
"id": "fda5a528-498f-47d4-bc29-a7a1c13774c3",
"uuid": "5jk5xmlb"
},
# More articles below this one
This is our target.
Parsing The Metadata
So we found an endpoint, now we need to tell our reader how to parse it. My chosen reader has always been FreshRSS but other readers have functionality similar to this as well (unless you’re using something god-awful expensive for what it is cough Feedly cough).
Anyway, this is the article definition for FreshRSS, with the out of sight feed URL pointing at https://www.warhammer-community.com/api/search/news/ and website URL pointing at https://www.warhammer-community.com/en-gb/all-news-and-features/:
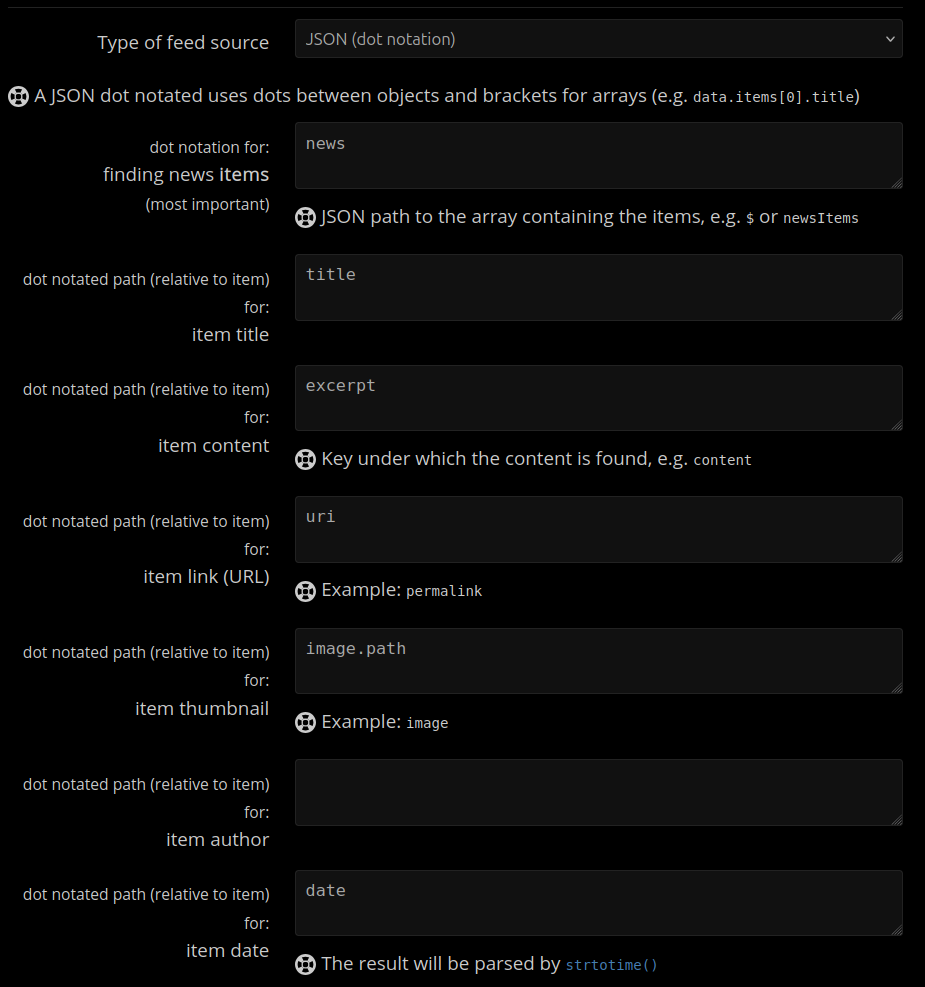
This is operating in JSON dot notation mode. Dot notation is a common mapping standard, used most commonly by the jq command in UNIX systems. This is essentially JSON’s version of XPATH, denoting an exact path to a specific value in a JSON document.
In essence, the configuration above tells FreshRSS exactly where the title, summary content, date, image and link are located for each article. It also tells it where the JSON array is which contains new articles. This is all we need to grab articles and import them into our reader:
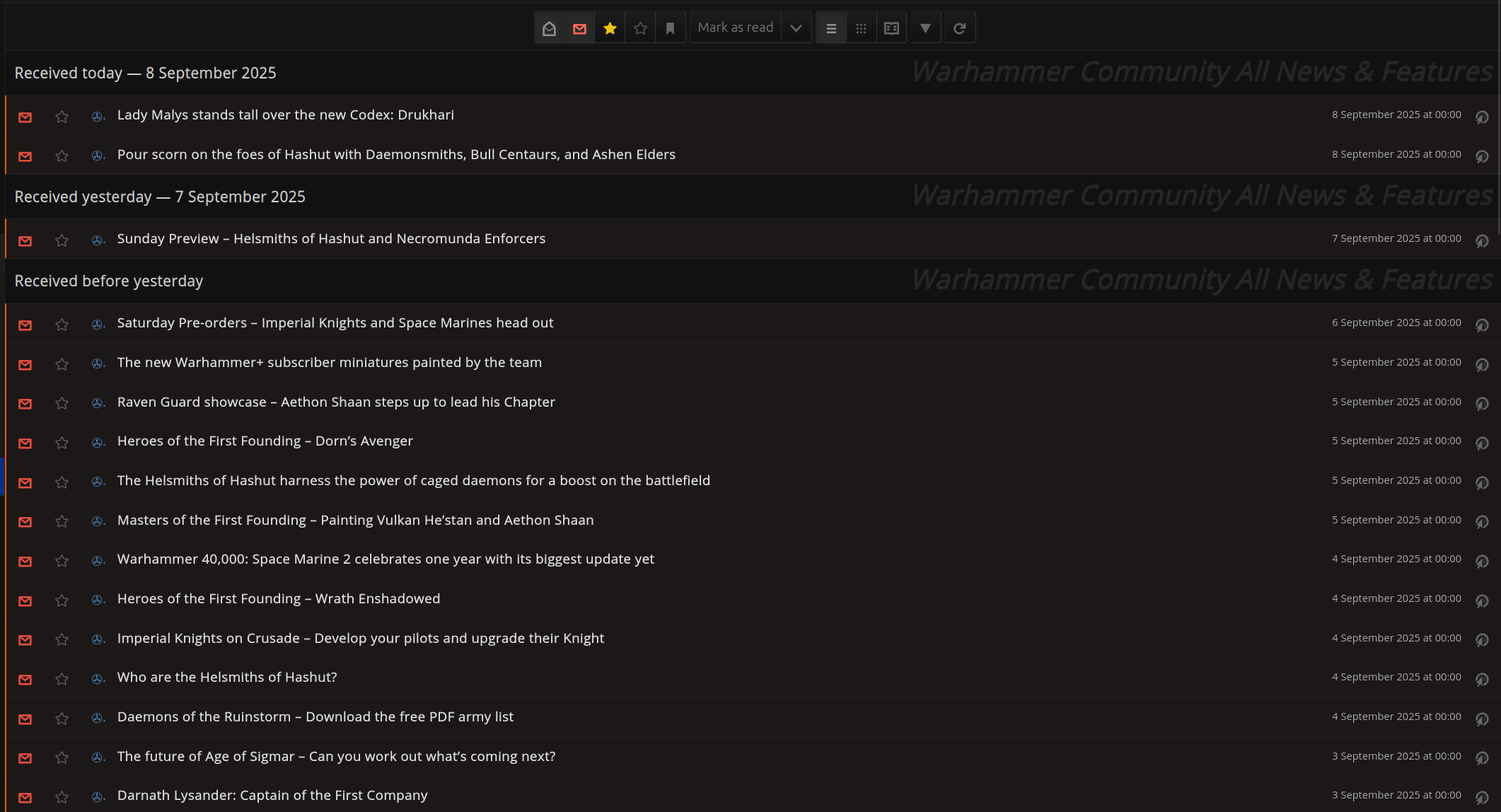
Applying This Elsewhere
You can use this same process for other sites and readers. So long as your reader supports whatever format the API responds with (JSON, CSV, etc) and so long as the API does not limit requests to allow-listed origins, you should be fine.
Till next time gamers 🖤